什么事动态规划?
动态规划(Dynamic Programming,简称dp),是把一个复杂的大问题拆成若干个相对简单的小问题来求大问题的方法。
dp是一种思想,而不是一种特定的算法。
基础DP
简单入门
求阶乘
给你一个数n,求出来1!到n!。(1<n<=15)
因为n!=1∗2∗3∗......n,所以可以对每个数的阶乘写一个for循环来计算。
1
2
3
4
5
6
7
8
9
10
11
12
| #include<iostream>
using namespace std;
int main(){
int n;cin>>n;
for(int i=1;i<=n;i++){
int ans=1;
for(int j=1;j<=i;j++){
ans*=j;
}
cout<<ans<<' ';
}
}
|
结果是正确的,但是太慢了。但是我们发现,n!=1∗2∗3∗4...∗(n−1)∗n,(n−1)!=1∗2∗3∗4...∗(n−1),所以n!与(n−1)!只有多层一个n的差别。所以可以得出,n!=(n−1)!∗n。但是我们在算n!之前,(n−1)!已经算出来了(n=1除外)。所以我们可以把每次算出来的阶乘放到dp数组中,要算下一个阶乘时,直接吧dp数组里存的前一个数组乘上这个数,就能得出这个数的阶乘。
1
2
3
4
5
6
7
8
9
10
11
12
| #include<iostream>
using namespace std;
int dp[20];
int main(){
int n;cin>>n;
dp[1]=1;
cout<<dp[1]<<' ';
for(int i=2;i<=n;i++){
dp[i]=dp[i-1]*i;
cout<<dp[i]<<' ';
}
}
|
在这其中,有一个重要的方程:dp[i]=dp[i−1]∗i。它描述了如何从已经算出的数据得到新的数据。这种方程叫状态转移方程。
状态转移方程中,状态经常指上一阶段做出的决策的结果。由已经推出的状态(结果)推出新的结果,就是状态转移。
数字三角形[IOI1994]
题目地址:(P1216)
有一个高度为r的三角形。
写一个程序来查找从最高点到底部任意处结束的路径,使路径经过数字的和最大。每一步可以走到左下方的点也可以到达右下方的点。输出那个可能得到的最大的和。
1
2
3
4
5
| 7
3 8
8 1 0
2 7 4 4
4 5 2 6 5
|
在这个题目中,我们可以遍历每一条路径,来求到达这个点时的最大值(下文简称最大值)。但这样的做法复杂度是O(2r),太慢了。
但是我们可以发现,到达每个点时的最大值是这个点左上角的点时的最大值(如果它左上角有点的话)和这个点右上角的点的最大值(如果它右上角有点的话)加上这个点的值。当三角形中的所有最大值都求完时,我们只用找出最下面一层的最大值,就是这个三角形可能得到的最大的和。
所以我们可以创建一个数组m,把已经求出来的最大值放进m中。当我们需要访问上一层左边的一个点的最大值或者上一层右边的一个点的最大值的时候,可以直接访问m数组。由于我们要保证求每一个点最大值时,它上一层左边的点的最大值(如果它左上角有点的话)和它上一层右边的最大值(如果它右上角有点的话)要先求出来,所以我们要从上向下求。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| #include<iostream>
#define GET(i,j) ((i<=r && i>=1 && j<=i && j>=1) ? m[i][j] : 0)
using namespace std;
int r,ans=-1;
int t[1010][1010],m[1010][1010];
int main(){
cin>>r;
for(int i=1;i<=r;i++){
for(int j=1;j<=i;j++){
cin >> t[i][j];
m[i][j] = max(GET(i-1,j),GET(i-1,j-1))+t[i][j];
}
}
for(int i=1;i<=r;i++)
ans = max(ans,m[r][i]);
cout<<ans;
}
|
这个题的状态转移方程为m[i][j]=max(m[i−1][j−1],m[i−1][j])+t[i][j]。
再看状态转移方程
这个题的状态转移方程中有一个max,它控制着每一步都能选出到达时最大值更大的一步。这就是动态规划的**最优化原理(最优子结构性质) **。
最优化原理(最优子结构性质) 最优化原理可这样阐述:一个最优化策略具有这样的性质,不论过去状态和决策如何,对前面的决策所形成的状态而言,余下的诸决策必须构成最优策略。简而言之,一个最优化策略的子策略总是最优的。一个问题满足最优化原理又称其具有最优子结构性质。
——摘自百度百科
在每一次决策中,只有m[i−1][j−1],m[i−1][j],t[i][j]和m[i][j]有直接关系,而数组m和t中的其他元素和m[i][j]没有直接关系,而m[i−1][j−1]和m[i−1][j]可以简单地视为数组前面元素的总结。这就是动态规划的无后效性。
无后效性将各阶段按照一定的次序排列好之后,对于某个给定的阶段状态,它以前各阶段的状态无法直接影响它未来的决策,而只能通过当前的这个状态。换句话说,每个状态都是过去历史的一个完整总结。这就是无后向性,又称为无后效性。
——摘自百度百科
m数组存储着每一步的状态结果,在根据一个新问题去找其中需要的旧问题的状态时,不用再求一遍,只要访问m数组就行了。这就是动态规划的子问题的重叠性。
子问题的重叠性 动态规划将原来具有指数级时间复杂度的搜索算法改进成了具有多项式时间复杂度的算法。其中的关键在于解决冗余,这是动态规划算法的根本目的。动态规划实质上是一种以空间换时间的技术,它在实现的过程中,不得不存储产生过程中的各种状态,所以它的空间复杂度要大于其它的算法。
——摘自百度百科
过河卒[NOIp2002普及组]
题目地址:(P1002)
棋盘上 A 点有一个过河卒,需要走到目标 B 点。卒每一步可以向下、或者向右。同时在棋盘上 C 点有一个对方的马,该马所在的点和所有跳跃一步可达的点称为对方马的控制点。因此称之为“马拦过河卒”。
棋盘用坐标表示,A 点为(0,0)、B 点为(n,m)。
现在输入B的坐标和马的坐标,要求你计算出卒从A点能够到达B点的路径的条数,假设马的位置是固定不动的,并不是卒走一步马走一步。
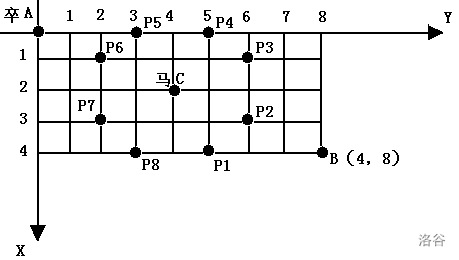
我们先定义一个二位数组dp,把到达某点时的路径总数存到dp中。
因为每一个卒都可以向下向右走,所以在到达某一点(设这个点为(x,y))之前肯定有向下或者的向右运动的操作(A点除外),所以在到达这个点时一定是从(x−1,y)或者(x,y−1)走来的。显然,可得出到达(x,y)时的路径总数为到达(x−1,y)时的路径总数加上到达(x,y−1)时的路径总数。可推出dp[x][y]=dp[x−1][y]+dp[x][y−1]。
但是,马的控制点是不可到达的,所以到达马的控制点的路径条数为0,也就是要强制dp上马的控制点的坐标为0。过河卒是可以到达点A的,而且只有一条(啥也不动),所以dp[0][0]为1。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| #include<iostream>
#define GET(i,j) ((i>=0 && j>=0) ? dp[i][j] : 0)
int controlPoints[8][2] = {{-1,-2},{-2,-1},{-2,1},{-1,2},{1,-2},{2,-1},{2,1},{1,2}};
using namespace std;
int n,m,hn,hm;
long long dp[25][25];
bool isControllable(int x,int y){
if(x==hn && y==hm)return true;
for(int i=0;i<8;i++)
if((x+controlPoints[i][0])==hn && (y+controlPoints[i][1])==hm)
return true;
return false;
}
int main(){
cin >> n >> m >> hn >> hm;
dp[0][0]=1;
for(int i=0;i<=n;i++)
for(int j=0;j<=m;j++)
if(!isControllable(i,j) && i+j!=0)
dp[i][j] = GET(i-1,j) + GET(i,j-1);
cout<<dp[n][m];
}
|
总结
上面三个都是非常简单的例题,我们只要容易地推出方程并稍加判断就AC了。
01背包
基本模型
01背包,顾名思义,就是在容量有限的背包里装尽量多的物体,每个物体可以装(1)或者不装(0)。
给你N件物品和一个容量为V的背包。第i件物品的体积是c[i],价值是w[i]。求解将哪些物品装入背包后,背包不会过载,而且使装入的物品的总价值最大。
用暴力怎么做
我们可以枚举每个物品放或者不放,再将放了的东西的体积和价值分别加起来,如果体积和小于等于背包的容量,那么让答案在答案和价值和之间取最大值。
//没写完
最长公共自序列
最长不下降子序列

